[数据库笔记]: 简单理解数据库恢复和ARIES算法
休止千鹤 | 02/07/2022recovery
这是一篇学习笔记,自己修改了一下,发出来吧。
数据库恢复等级分类
- R1: 没有commit的事务中出现错误,必须回滚。
- R2: 内存出现错误,已经完成的事务必须保存。
- R3: 内存出现错误,未完成的事务必须回滚。
- R4: 外存出现错误,哦豁,硬盘坏了。我不会修硬盘,这里不提。
这几个等级恢复可能性和发生可能性依次递减。恢复所需时间依次递增。
恢复原理
- 可重置条件
在历史记录中若$w1(A)<_H r2(A)<w2(B)<_H commit2$(事务1写入对象A然后事务2读取A,而后事务2写入B,最终事务2被提交)这种情况下T1(事务1)是不可重置的,因为T2读取了T1并且已经在最后提交。T2的结果很可能受到了T1的影响。试想我给你了100块钱是事务1,你又给了别人转了100块钱这是事务2。这个时候重置岂不是我100还有100块,别人白捡了100。
所以: T只能在其后事务读取后仍然没有提交的情况下才可以重置。
- 级联终止
在历史记录中出现了$w1(A)<_H r2(A)<_H w2(B)<_H abort1$ 假设T2读到了T1刚刚在A中写的一个不合法的值,最后发现有问题,所以这下必须T2和T1都要回滚。
所以:一个事务终止时必须带着它读过的事务一起回滚回去。
这听起来太可怕了。但是它并不会影响到已经提交的事务。也就是说比如上述例子事务T2回滚前若T1已经提交(commit)或者被终止,那么级联终止就不会发生。
- 严格模式
回滚事务的时候,我们当然希望每个单独的写操作都能回滚到写之前的样子(before image)。但是这样也可能导致错误。
比如: $w1(A)<_H w2(A)<_H abort1 <_H abort2$ 假设A是你的银行账户,原来有100块钱,事务1中你又存了一笔100,此时你账上有200了。事务二中你又想存一笔100,此时你应该账上有300块钱。可是这个时候事务1出了问题,表示要回滚,钱退你。回滚到事务1发生前,你原来有多少钱呢?100块钱,这好像有点不太对。还没完呢。这个时候事务2也出了问题喊着撤销,再退你100。这个时候嘛,200块钱也退你了。emmm好吧,没问题。就在你松口气的时候看了眼余额。你的账上却是200块钱!你之前明明只有100!
怎么回事?因为w2之前是200啊。你拿回了想存的200块钱,但是你的余额是200。你凭空账上多了100。
T1的运行终止留下了的无效值,被T2当做有效。
我们需要严格模式,T2必须等T1出了结果(提交或终止)后才执行。
理解Steal,force
我相信你们很多人都知道,数据库存储架构有两块: 一部分在内存里,另一部分在磁盘。硬盘访问一次的代价太大。内存中是一个缓冲区。数据库的常用部分临时存储在内存,比如对事务的操作等等,可以尽可能避免不必要的硬盘访问提高数据库性能。但是内存中也有个问题:断电数据就没了。
而数据库内存管理的单元是固定大小的单元管理数据库信息,而这通常被称为页(Page)。
如果你了解过mysql的InnoDB的内存,你会发现主要被分为Buffer Pool和Log Buffer。而Log Buffer就是为了做Redo Log。通常,一台Mysql数据库服务器会有很大的内存。而绝大多数内存都会被分给数据库服务。Buffer Pool越大,可以缓存更多的数据。更多的操作也会发生在内存,可以提高性能。我的博客系统没有用Mysql的原因是我的服务器只能租的起512M的内存,mysql显得有些臃肿。虽然mysql可以设置innodb_buffer_pool_size但是我用了别的方案。这里不提。
关于缓存页何时写入硬盘有几个管理模式:
- steal:
- 当需要替换时,任何页都是可能被写入硬盘的。因为steal可能把没有做完的事务写进硬盘。
- 这种情况下如果出现错误恢复比较麻烦,因为要追溯哪个是脏页(做了一半还没结果的事务),需要日志和WAL规则(一会说)进行UNDO(撤销恢复)。
- 但是这样性能会有大幅提高。你可能会问什么场景会要替换?比如缓冲区满了,但是现在有东西要操作。steal允许腾出空间,但是no steal就必须等有事务结束后腾出空间。UNDO是性能的代价。
- no steal:
- 仍旧活跃的页不允许写入硬盘,硬盘没有脏页,都是已经结束的事务,因此不需要Undo。
- force:
- 事务commit后修改必须写入硬盘。
- 这样的好处是不需要找到谁还没写入,所以不需要REDO(重做)。
- 而且会花很多时间在硬盘I/O上面。性能差。
- no force:
- 事务commit后不一定写入硬盘。所以性能更好。提交时只有REDO信息被写入日志。
- 缺点和steal一样,恢复时代价更大。
附一张表
| force | no force | |
|---|---|---|
| steal | undo/keinRedo | undo/redo |
| no steal | keinUndo/keinRedo | keinUndo/Redo |
我们可以知道,steal,no force的组合在运行的时候是最快速的。no steal, force的组合是最慢的。但是恢复起来情况相反。
这里引用慕尼黑大学 PD Dr. Peer Krög的讲义里的图:
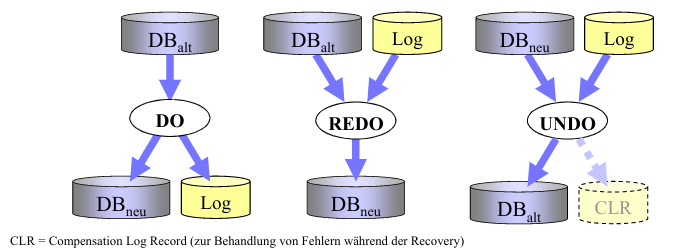
写入策略
- Update in Place: 每个页都有自己的位置,写入就在页面上会被覆写。
- Twin-block: 每个页都会有一个副本,并且位置连续。
- Shadow-storage: 只有在被修改的时候会有副本,比Twin-block冗余更少。
日志
简而言之,日志是由有序的,描述改动的条目:
- 被修改的页的地址
- 执行操作的事务ID
- 记录了Before-image和After-image的页
一部分的日志在内存,一部分会被写入硬盘的日志文件。那些长久积攒的日志,会被归档起来。
日志会跟随者缓冲区的更新而更新。在进行恢复的时候,我们需要日志,看看当时做了什么操作。
哦,对了,如果你还记得恢复等级的话,那些硬盘里的日志文件用来做R1到R3恢复,至于归档,是用于R4恢复的。
事实上日志也有很多种。有逻辑日志,物理日志等等(Logical Log, Physical Log)。不过这里不提了。只是给ARIES的日志开个头。
ARIES: Algorithms for Recovery and Isolation Exploiting Semantics
(怎么翻译呢…利用语义的恢复和隔离算法?)
别被吓到。ARIES是一个恢复算法。可能你听着有点陌生,但是从当年的DB2到Oracle,mssql,mysql,postgresql都有ARIES的应用。
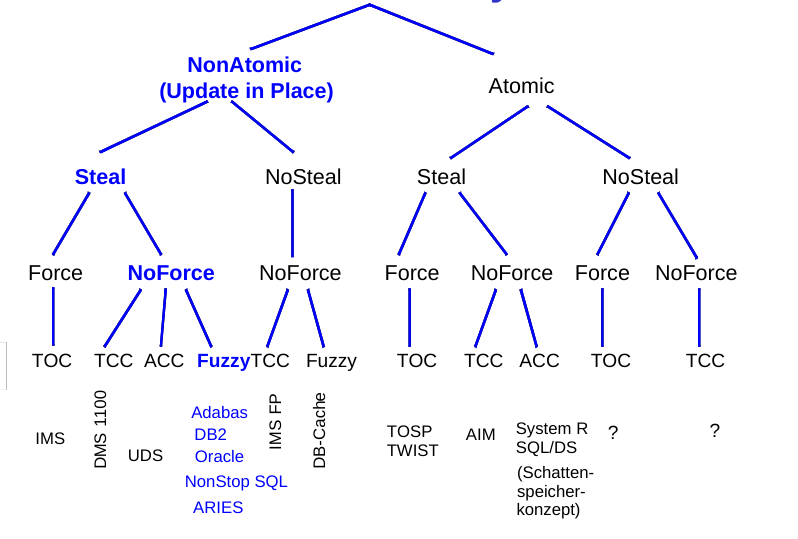
图来源于莱比锡大学讲义 Prof. E. Rahm 来源见最后参考
ARIES具有:
- Steal
- 脏页可被写入硬盘。
- No force
- 有变动的页面可能不再硬盘里。
- Update in Place
- 所有页面在内存中只有一份。
- 小锁粒度
- 在单句级别,解释一下:加锁的粒度不再是对页面加锁,不同事务可以同时处理同一个页。这也意味着这这个页同时包含结束和未结束的两种状态的事务的数据。
ARIES遵循WAL原则:
- 在事务commit之前,必须把和这个事务有关的所有日志写进硬盘。
- 在置换脏页进入硬盘之前,这个页的日志也必须先写到硬盘。
这样的话出现任何意外我们直接可以用日志进行回滚恢复。日志保证有,但是不知道还做没做就是了。这个不重要,因为恢复时还会写。
ARIES的日志有:[LSN, XID, PageID, Redo, Undo, PrevLSN]
- LSN: Log Sequence Number
- 它是每一条log的编号,时序单调递增。
- XID: 每个事务的ID(简化版本合并了Log Type)
- PageID:执行更改操作的页面的ID。(这里也简化合并了页内偏移地址,就当…不存在。)
- Redo:Redo时应该执行的操作。
- Undo:Undo时应该执行的操作。
- PrevLSN:上一个操作的LSN,便于Undo跟踪。
(我这里的ARIES会是一个简化的ARIES,更好理解。实际上会复杂一些。)
数据库恢复(简化)
- 分析
- 分析日志文件,从上个Checkpoint分析。
- 检查winner事务,归入一个列表中。winner是指:在崩溃之前日志中有commit了的事务。
- 检查loser事务,归入一个列表中。loser事务是指:在崩溃之前日志中没有commit的事务。
- Redo
- 日志所有条目按正向顺序检查重做。不管是winner还是loser。
- 若当前日志里扫描到的那条的LSN比写入数据库写入结果保存的那条LSN更加小,意味着后面已经写入硬盘,这里不需要重做。
- Redo的目的是恢复到意外出现前数据库的状态。
- 打个比方。你转了三次账,数据库已经提交写入了你这是第二次转账,和第二次转账后的余额,处理你第三次转账时做一半就崩溃了,那么第一次转账扣款不需要重做。节省时间。
- Undo Loser事务
- Loser事务会被回滚,按照逆序,写个CLR再回滚。
- 也打个比方,还是你转了三次账。数据库还是在处理第三次时出了事,事务内部你的账户被扣了钱,还写进了硬盘。可是这会别人账户还没加钱呢,就这时候数据库电源给人一脚踢掉了。恢复程序Redo后一看,哦豁,硬盘里也是你第三次转账后剩下的余额。这个时候事务接下来要做啥也不知道,甚至这转账是给谁转都不知道。怎么办?回滚呗。至于第一次和第二次转账,都commit了,也在Redo的时候肯定都写入硬盘了。所以不用管。这就是为什么我们要Undo,并且只Undo那些Loser事务。
CLR是啥
CLR是Compensation Log Records 。你想,还是刚刚的例子。Redo做完了的时候,就像什么事都没发生一样。只是之前的事务后来要做啥,数据库也不知道。回滚,可以。但是如果回滚的时候老鼠又把电线咬了怎么办?谁知道回滚到哪里了。Redo只要有之前硬盘的数据和日志,都能还原“案发现场”,但是撤销那些事务做的事情的时候出了岔子就不好了。总得有个什么记着点吧。
于是有了CLR:[LSN, XID, PageID, Redo, PrevLSN, UndoNxtLSN]
和之前的日志对比,它少了Undo的信息,但是多了一个UndoNxtLSN。
CLR是一种特殊的日志。它可以把Undo也看做一种操作。我们刚刚说了Redo就是为了还原“案发现场”,那么Undo操作也是这案发现场的一部分,也可以被Redo还原就好了。没有Undo是因为CLR不需要Undo。至于UndoNxtLSN是为了保存恢复的进度,好让Undo一半崩溃掉的数据库再次恢复时可以接着做。
Checkpoints
我们刚刚提到,分析,Redo的开始是一个Checkpoint。Checkpoint本身不难理解,你打游戏就有一堆Checkpoints,存档点。
我们认为Checkpoints之前都是好的。至于Checkpoint之后出了问题,就从Checkpoint恢复重来呗。没有存档点就很麻烦了。出了点问题,你就得整个重新再来。
但是Checkpoint设置是有点麻烦的。你想哦,设计多了,开销太大。设计少了,恢复就很麻烦;我们不想在Checkpoint把事务拆开,带着脏页。我们我们通常希望在没有事务活动的时候当做一个存档点。集中把页写进硬盘,整理一下日志什么的。但是哪有这么好的事?
事务一致Checkpoint
- 或者我们可以暂时不进行新的事务,等待那些活跃事务自己跑完结束以后做个Checkpoint再恢复?这个叫做事务一致Checkpoint。
- 但是这样搞延迟太大了啊。谁知道一个事务跑多久。
行为一致Checkpoint
- 或许也可以让粒度更小,先把日志和数据库缓冲区写进硬盘,再把当时活跃的事务和那个所有压在Checkpoint上的事务的最早的那个操作LSN记下来?
- 这个样子直接把没有提交的数据写进了硬盘,而那个压在Checkpoint上的事务可能运行有一会了,它最早操作的(即最小)LSN都不知道早到哪里去了。这样的Checkpoint并不在一个精确的位置上。
Fuzzy Checkpoint
- 于是ARIES直接…给页做了异步同步,直接把脏页列表,活动页列表,最小脏页LSN和最小事务LSN都整过去了。这个叫做Fuzzy Checkpoint。
- 因为这不是一个point。像极了你小学在几何图形的某线段上打点打歪,故意把点涂大的样子。这样子做也可能导致没有提交的更改写进硬盘。并且Undo和Redo很明显也可能会因为miniLSN偏离Checkpoint。
参考
一文讲懂 ARIES Recovery 算法 写的很好了。推荐阅读。
Views:
Comments
VeiledTiger:
谢了bro,正在被作业拷打,看了你这个文章有些思路了
Reply